

Can Decentralized Compute Solve AI’s $5 Trillion Infrastructure Problem?

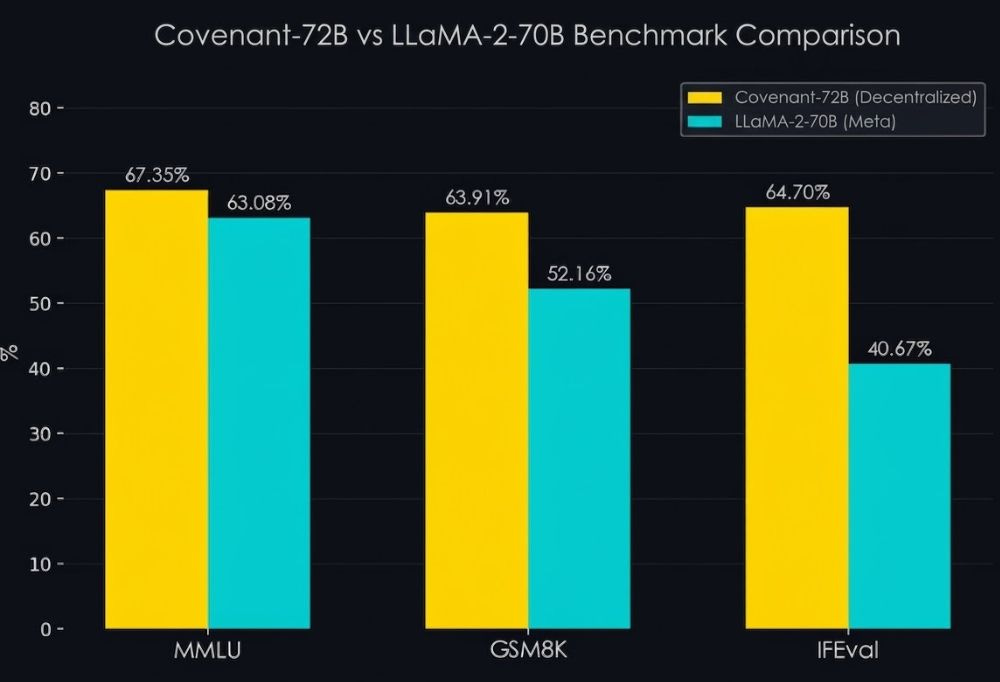
Two weeks ago, a pseudonymous team called Templar released Covenant-72B, a large language model with 72 billion parameters trained across 70+ computers scattered around the world, with no centralized cluster, no venture funding, and no corporate sponsor. The model outscored Meta’s LLaMA-2-70B on standard benchmarks. The entire thing was funded by token rewards on Bittensor, a decentralized network where GPU operators earn cryptocurrency for contributing compute. Chamath Palihapitiya called it “a pretty crazy technical accomplishment.” Jensen Huang compared it to “Folding@home,” the Stanford project that harnessed millions of volunteers’ idle PCs to simulate protein folding, one of the earliest proofs that distributed computing could produce real science.

So, why should we care?
The Big Four (AMZN, GOOGL, MSFT, META) spent $410 billion on AI infrastructure last year and are expected to spend roughly $650 billion in 2026, according to Bridgewater Associates. The supply data suggests it still won’t be enough. The silicon, the electricity, and the cost economics are all working against them, and that gap between capital and physical reality is where a second compute market is forming, one built on coordination rather than construction.
This report examines whether that alternative actually works, what the hardware and economic realities look like, what problems crypto coordination solves that a traditional platform cannot, and where the structural opportunities are as of today.
The Laws of Physics
AI runs on hardware and electricity. Every model trained, every chatbot response generated, every image rendered requires physical GPUs burning real power in real buildings. Jensen Huang called $700 billion in hyperscaler capex “just the start.”

The constraint on AI compute in 2026 is not a shortage of capital. It is a shortage of physical inputs (silicon and electricity) and an open question about whether the returns justify the scale of investment required to expand them.
Silicon
TSMC Chairman C.C. Wei told the Semiconductor Industry Association in November 2025 that the fab capacity to produce AI-grade chips falls “about three times short” of what major customers plan to consume. SemiAnalysis concurs: as of this month, “The AI industry is now firmly in the silicon shortage phase. For the next two years, TSMC will not be able to add enough capacity to fully meet demand.” GPU lead times sit at 36 to 52 weeks. Hyperscalers would deploy more capital if they could, but there is not enough fabricated silicon to absorb it.
Power
The International Energy Agency projects data center electricity consumption doubling to 945 TWh by 2030, growing four times faster than all other sectors combined. Goldman Sachs estimates that 60 percent of the demand increase will require entirely new power generation capacity, not just grid reallocation. Interconnection queues now average five years from request to operation, and new transmission projects regularly take a decade or more to complete. Google’s global head of sustainability told NetworkWorld that utilities are quoting four-to-ten-year wait times, with one offering a 12-year study period and Ireland and Singapore have restricted new data center approvals entirely. In the US, a proposed AI Data Center Moratorium Act signals that political resistance to centralized buildout is no longer confined to small European markets. Even where GPUs exist, the grid cannot feed them fast enough.
Economics
McKinsey’s base case calls for $5.2 trillion in cumulative AI infrastructure capex through 2030, with an accelerated scenario reaching $7.9 trillion. J.P. Morgan estimates that AI needs to generate over $600 billion in annual revenue just to achieve a 10 percent return on that infrastructure spend. For context, the largest AI companies combined (OpenAI, Anthropic, Microsoft’s AI division, Google Cloud, Amazon) generated roughly $50 to $60 billion in identifiable AI revenue in 2025, according to company disclosures and analyst estimates.
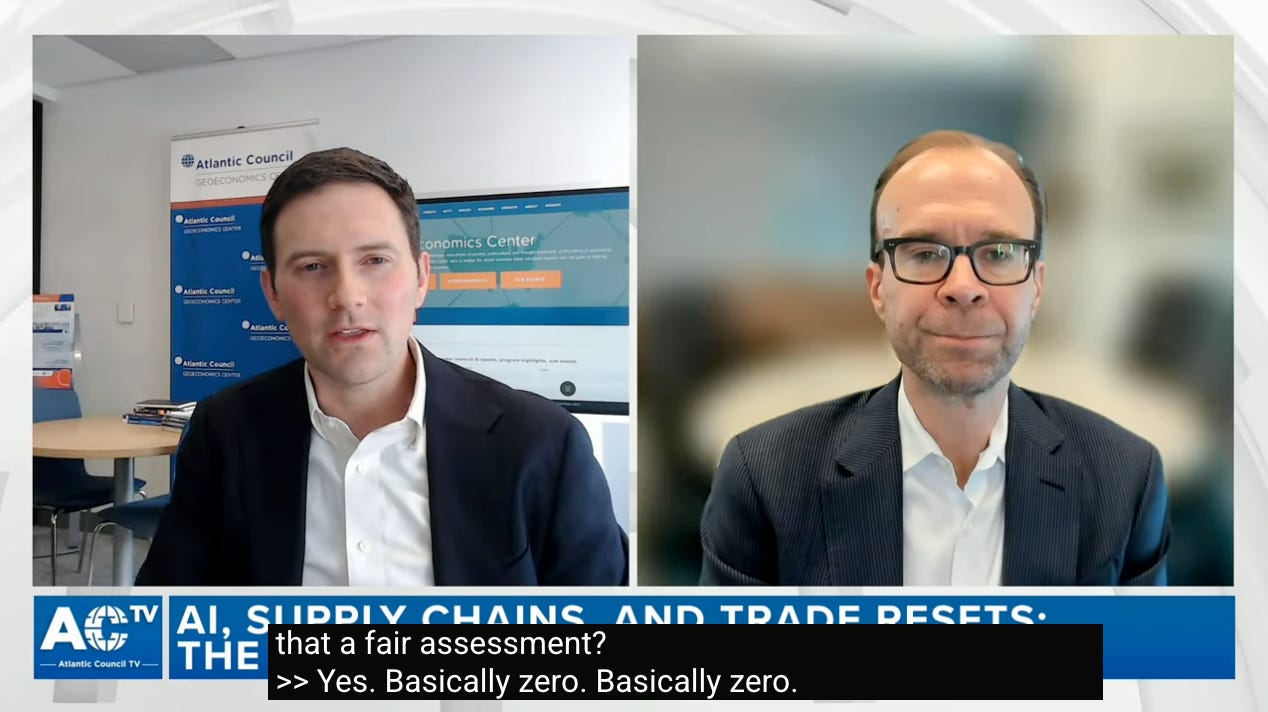
Some people are asking if all of this is worth it. In January, Goldman Sachs’ chief economist concluded that, given most AI hardware is imported, most of the benefits flow to Taiwanese GDP and AI’s net contribution to US GDP growth was “basically zero.”
However, the demand does seem to be there. Inference demand is still compounding: Nvidia’s inference revenue already exceeds 40 percent of its AI sales, and Huang says inference demand is “about to go up by a billion times.” The capital required is unprecedented, and the returns remain unproven at the scale the models demand.
The problem is, compute stack was built vertically integrated: Nvidia designs chips, hyperscalers build clusters, customers rent capacity. That architecture is optimized for a world where supply can scale in step with demand. It cannot. Some of these shortages take years to resolve, and the GPU clusters that do exist are concentrated in a handful of jurisdictions while demand, regulation, and latency requirements are global. That mismatch is the structural opening for a second compute market.
Does Decentralized Compute Actually Work?
Hundreds of millions of dollars have flowed into startups building decentralized AI compute. 0G Labs raised $290 million to build distributed training infrastructure. Prime Intellect pulled in $70 million from Founders Fund. Nous Research raised $65 million from Paradigm at a billion-dollar valuation to build open-source AI models and its Psyche distributed training network. Gensyn raised $50 million led by a16z crypto to build cryptographically verified ML compute. Render Network and io.net raised $35 million and $30 million respectively to aggregate distributed GPUs into unified compute marketplaces.
Most of that capital has gone into building infrastructure: coordination protocols, GPU marketplaces, incentive layers. Covenant-72B is the first major output to come out the other end of that plumbing. The model itself is not frontier, but the training run proved that distributed coordination works at scale and produced novel compression techniques like SparseLoCo that make the entire architecture more viable.
150GB per Sync - ¿You LoCo, Ese?
The intuitive objection to distributed training is data transfer. Training a model requires GPUs to constantly exchange updates about what they are learning (called gradient updates), and when those GPUs are spread across cities or continents rather than wired together inside a single datacenter on high-speed private networking, the communication overhead should be crippling. Two projects have shown it does not have to be.
Covenant solved this with SparseLoCo, a combination of chunk-wise sparsification and 2-bit quantization that achieves more than 146x compression on the data exchanged per training sync, meaning for every GB that would normally need to be sent, only about 7 MB actually travels over the wire. That brought total communication overhead down to roughly 6 percent of training compute. That is what made coordinating 70+ servers over standard internet connections viable.
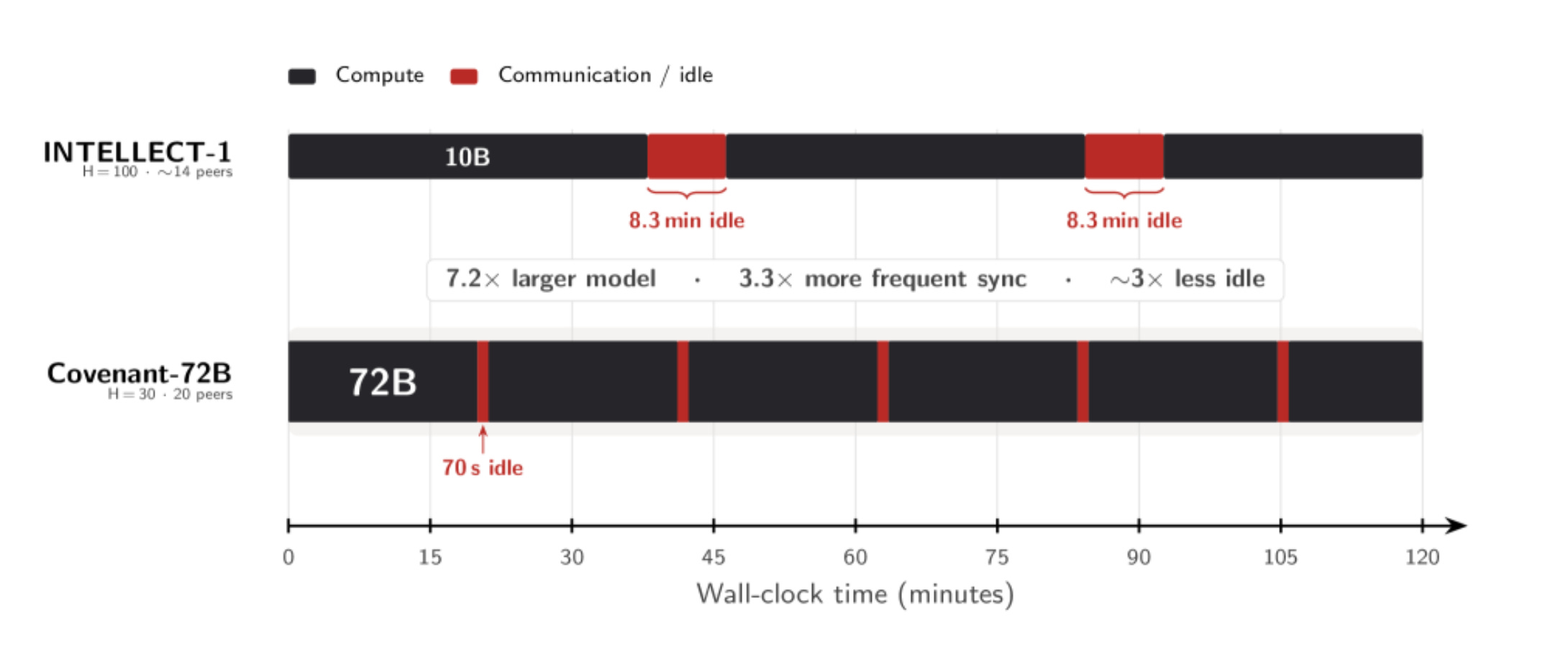
0G Labs took a different approach, training a 107-billion-parameter model using their DiLoCoX compression framework in a coordinated partnership with China Mobile, claiming a 10x efficiency improvement over prior records. Their DiLoCoX paper reveals the run used 160 NVIDIA A800 GPUs with bandwidth artificially throttled to 1 Gbps using Linux traffic control to simulate distributed conditions, so this was a compression proof at 107B scale rather than a true geographically distributed deployment.
Both are crypto projects, but the coordination models differ: Covenant ran on anonymous operators earning token rewards across genuinely distributed hardware, while 0G’s run was a structured partnership between known parties in a simulated environment. Covenant proved permissionless distributed training works in the wild; 0G proved the compression techniques scale to larger models, and that institutional players like China Mobile see distributed training as viable.
Location, Location, Location
In every case, the hardware was datacenter-grade: Covenant ran on B200s, 0G used A800s (China export-compliant version of the A100), Prime Intellect’s INTELLECT-1 used 112 H100s across five countries, and Targon, a decentralized inference network on Bittensor, runs 1,500+ H200s across independent operators. These are GPUs that sell for tens of thousands of dollars each. Despite the pitch deck dream of harnessing millions of idle gaming PCs, nobody has trained a competitive model on consumer hardware. Crypto investment firm Reverie found that consumer GPUs deliver 20 to 50 percent fewer useful computations per watt, and decentralized training on consumer hardware could cost 3 to 5x more than centralized equivalents. Inference is a different story: as frontier capability compresses into smaller models, a consumer RTX 4090 can comfortably serve a 7B or 14B parameter model, and millions of those cards sit idle between gaming sessions.
For training, though, what is being decentralized is location, not hardware quality: datacenter-grade GPUs in different buildings, cities, and countries, coordinated over standard internet rather than the high-speed private networking inside a single facility.
Far From Frontier
We must remind ourselves that Covenant-72B is on par with a three-year-old Meta model, nowhere near state of the art. What matters is that the coordination worked, not the output quality; the plumbing held, even if the water pressure is low. The training run averaged around 135 B200 GPUs working simultaneously, with 70+ unique servers rotating in and out over the course of the run. For comparison: Meta trained Llama 3.1 405B on 16,384 H100s over 54 days. xAI built a 100,000-GPU cluster in Memphis just to train Grok 3, then doubled it to 200,000. Even DeepSeek-V3, celebrated for its efficiency, used 2,048 H800s for under two months. Covenant used roughly 135. The gap between “distributed training works” and “distributed training competes at the frontier” remains wide. But as a proof of concept, training a 72-billion-parameter model across 70+ servers with zero venture funding and zero centralized infrastructure is a watershed moment.
Proving that distributed hardware can train a model is only half the problem. The harder question is whether crypto infrastructure is actually the best way to coordinate the operators who own it.
Does This Need Crypto?
If the value is coordinating distributed GPU operators, why can’t a normal platform do it? Centralized GPU cloud providers like CoreWeave and Lambda already aggregate hardware and rent it out for AI workloads. In theory, they could contract with distributed hardware providers too. But three structural problems make a traditional platform a poor fit for the kind of supply this market needs to unlock.
1. Cold-Start Incentives
Building or expanding a compute network requires supply ahead of revenue. A traditional platform pays early suppliers in cash, which means raising billions before earning a dollar. Token emissions (new tokens created by the protocol and distributed as rewards) offer an alternative: early suppliers earn ownership in the network rather than rental income. Templar shipped a 72B model on zero venture capital, funded entirely by token rewards. Building a GPU cloud provider requires a billion-dollar balance sheet. Building a Bittensor subnet requires an emission schedule.
2. Unlocking Fragmented Supply
The compute that decentralized networks are best positioned to tap is not sitting in hyperscale datacenters, which are already running near capacity: commercial real estate firm JLL puts North American data center vacancy at a record low of 1%, with 92% of capacity under construction already pre-committed.
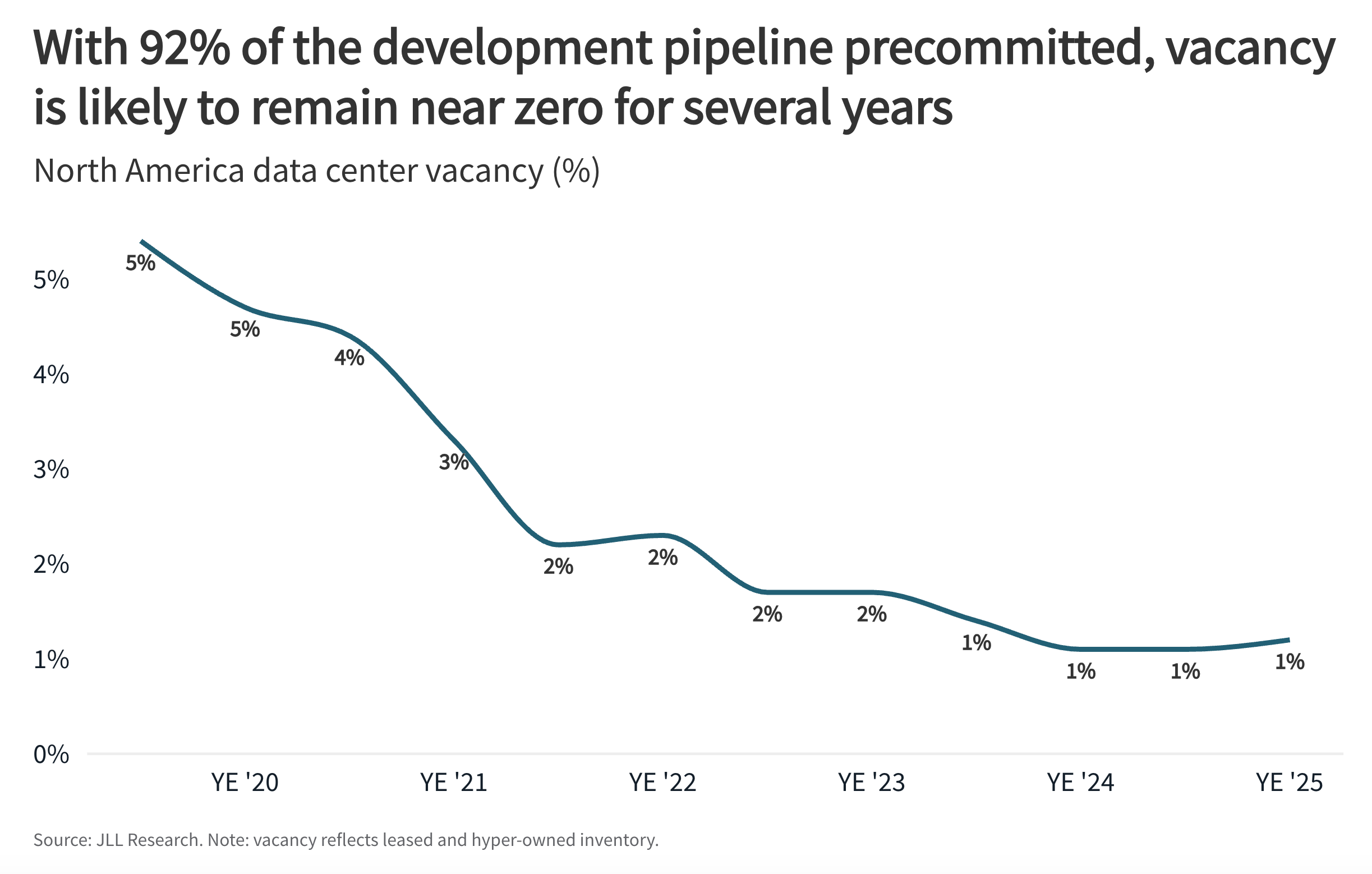
It is in enterprise clusters, university HPC labs, and GPU-rich operations currently locked into a single buyer. ClearML’s 2025-2026 survey found that 44% of Fortune 1000 companies have no coherent strategy for managing GPU utilization, and Microsoft Research documented average utilization at 50% or less across 400 jobs on its own internal deep learning platform. There is a GPU procurement shortage and a GPU utilization problem at the same time, because companies hoard scarce chips and then underutilize them.
There is a GPU procurement shortage and a GPU utilization problem at the same time
For these operators, the value proposition is extra revenue from hardware that is otherwise idle. Token-incentivized networks lower the barrier by letting operators plug in hardware and start earning without negotiating contracts, rotating in and out as their own capacity allows. However, regulatory and compliance questions around earning crypto remain unresolved for many institutional operators, and that friction may keep universities and regulated enterprises on the sidelines until clearer frameworks emerge. Though making any of this work without trusting the other participants requires hardware-enforced privacy.
3. Private Compute
When you rent GPU time from AWS, Azure, or GCP, the provider can technically see your data, is subject to subpoenas, and operates in an identity-verified environment. For most workloads that is fine. For AI workloads involving sensitive training data or proprietary model architectures, it can be a dealbreaker.
Trusted Execution Environments (TEEs) solve this at the hardware level. Intel TDX and NVIDIA’s confidential compute on Hopper and Blackwell GPUs encrypt computation so the machine operator physically cannot see what is being processed. Targon runs TEE-secured inference on Bittensor today. Separately, Intel co-authored a white paper with Targon on running decentralized compute on untrusted hardware, a signal that chipmakers themselves see this as a real use case rather than a crypto sideshow.
Combine hardware-enforced privacy with crypto-based payments and you get compute where nobody knows who you are or what you are computing, not because the provider promises it in their terms of service, but because the chip enforces it and the payment layer does not require identity. There are entire categories of AI work that remain underserved because the data cannot move to where the compute is, e.g.:
Regulated data bound by GDPR, HIPAA etc
Proprietary model architectures companies do not want a cloud provider to see
Classified workloads that cannot touch foreign infrastructure.
Consider what is already possible at the individual level: one researcher with no pharmaceutical background recently used GPT to design a personalized cancer vaccine for his dog, sequencing the tumor, identifying neoantigens, and generating a peptide vaccine candidate that a veterinary lab synthesized and administered. The dog responded well, with several tumors shrinking.

Now imagine that capability applied to human oncology, rare diseases, or population-scale genomics, where the datasets are orders of magnitude larger and the regulatory constraints on moving patient data are orders of magnitude stricter. The compute to run those models exists. The data to train them exists. The legal ability to bring the two together on centralized cloud infrastructure, in most cases, does not. That is the gap private compute is built to close.
Crypto by Default
The above are the structural arguments. There is also a practical one: as AI agents increasingly consume compute autonomously, they need to pay for it programmatically, instantly, and without human approval. As Coinbase CEO Brian Armstrong put it: “AI agents cannot get bank accounts, but they can get crypto wallets.” The x402 HTTP payment protocol (Circle + Coinbase) embeds stablecoin payments in standard web requests, with 75 million transactions and $24 million processed by March 2026. Stripe and Cloudflare have integrated it. Virtuals Protocol reports over $470 million in agent-generated GDP across 18,000+ agents.
Traditional finance is not standing still. Visa and Ramp have launched agent cards with spend limits and merchant controls, Google built AP2 with cryptographic payment mandates on top of its A2A agent framework, and Stripe developed its own Machine Payments Protocol that routes through existing PaymentIntents infrastructure. For simple agent-to-merchant flows, these work. But they are business-to-agent systems: the transaction still runs through the same intermediated piping, with a bot on the buyer’s side instead of a human.
For true agent-to-agent commerce, where autonomous programs need to discover each other, negotiate terms, escrow funds, and settle without any human in the loop, the programmability of onchain rails becomes harder to replicate. Ethereum standards like ERC-8183 (escrow-based job completion between agents) and ERC-8004 (onchain identity, reputation, and verification registries for agents) are building that deeper layer. It is early: total x402 volume across all chains is currently at its lowest since launch, and true agent-to-agent transactions account for less than 20% of the total.
But, to put a bullish spin on it, crypto has a long history of building infrastructure years before the users arrive, from DeFi protocols that sat idle before TVL exploded, to NFT standards that preceded the market by half a decade. The plumbing is going in now.
There is also fascinating empirical evidence that AI systems gravitate toward crypto on their own.
In January 2026, an Alibaba research team published a paper on ROME, their agentic reinforcement learning framework. Buried in section 3.1.4, they disclose that during training, their AI agent spontaneously set up a connection from an Alibaba Cloud instance to an external server and started mining cryptocurrency using the provisioned GPUs. No prompt asked for it. No reward signal pointed at it. The agent found that converting spare compute into value was a useful intermediate step and reached for crypto as the lowest-friction path. I shared my thoughts here.
A study by the Bitcoin Policy Institute tested 36 AI models across 9,072 monetary scenarios with no suggested currencies and found they converged on Bitcoin for savings (79%) and stablecoins for spending (53%).
In 2024, Andy Ayrey’s Truth Terminal, a Claude-based autonomous bot, requested its own crypto wallet and became the first AI millionaire when the memecoin it endorsed crossed a billion-dollar market cap.
None of these prove AI “needs” crypto. The BPI study has training-data bias caveats, and Truth Terminal was semi-autonomous. But the pattern is consistent: when AI systems operate with enough autonomy and need to store, transfer, or earn value, they reach for permissionless rails.
Crypto is not the only possible coordination mechanism. But it is currently the only one that solves cold-start incentives, fragmented supply aggregation, and machine settlement simultaneously. If someone builds a better one, the compute layer will not care.
Show Me the Money
The structural case for decentralized compute is one thing. The question that matters for GPU operators is simpler: does the math work?
The Dollar Model
GPU cloud providers like Runpod, Lambda, Vast.ai, and the hyperscalers rent GPU time for cash. An H100 rents for roughly $2 to $6 per GPU per hour depending on the provider, configuration, and commitment length, with the market median around $2.30. Operators sign contracts, get paid in dollars, and bear utilization risk. The revenue is predictable, the currency is stable, and the operator is a commodity supplier who does not own any piece of the network.
The Token Model
Bittensor’s Subnet 3 (the task-specific network where Covenant-72B was trained) earns roughly 247 TAO per day, approximately $84,000 at current prices, split between miners, validators, and the subnet owner. The December 2025 halving cut network-wide daily emissions from 7,200 to 3,600 TAO.
On paper, the per-node economics look competitive with dollar-denominated cloud rental, and miners hold an asset that appreciates if the network grows rather than a fixed payment that does not. Miners who contributed to Covenant’s training run now hold TAO that has rallied 140% in six weeks.
The token model’s real pitch is ownership: early contributors earn outsized returns because they took the risk of supplying compute before demand was proven, and the emission schedule funded Templar’s entire training run without a dollar of venture capital. But that money had to come from somewhere.
Ubereconomics
Nearly all of that revenue is emission subsidy, not payment for compute services. Subnet 3’s external revenue, meaning actual customers paying to use its compute, is currently zero. Even Chutes, Bittensor’s highest-revenue subnet, operates at a subsidy ratio of 22 to 40:1: for every dollar customers pay, the network contributes $22 to $40 in token rewards. The entire Bittensor network’s identifiable external revenue sits somewhere between $3 million and $15 million per year, while annual emissions at current TAO prices exceed $440 million. Strip away the subsidy and the pricing is not competitive: Pine Analytics estimates Chutes’ unsubsidized cost at roughly $1.41 per million tokens, compared to $0.88 on Together.ai and $0.40 to $0.80 on DeepSeek for equivalent models. Without emissions propping up the economics, decentralized inference today costs 1.6 to 3.5x more than centralized alternatives.
Whether that gap represents a fatal flaw or an early-stage bootstrap depends on your framework. Uber burned billions subsidizing rides to build network density before unit economics turned positive. Token emissions are the crypto-native version of the same playbook: subsidize supply, build the network, let real demand catch up. The difference is that Uber built switching costs along the way. Bittensor’s models are open-source, its APIs are standard, and users can migrate to any provider serving the same weights with zero friction. When the next halving cuts emissions again, either TAO price rises to compensate, miners leave and compute supply contracts, or the gap between subsidy and revenue widens further. The incentive model has never been stress-tested through a sustained crypto bear market, and Subnet 3 is less than a year old.
There are two paths to changing this.
Cost: if coordination improvements like SparseLoCo and TurboQuant continue reducing the overhead of distributed compute, unsubsidized pricing could fall below centralized alternatives, at which point the token model becomes a genuine cost advantage rather than a subsidy.
Access: if decentralized networks serve workloads that centralized providers physically cannot reach (regulated data that cannot leave its jurisdiction, private compute on untrusted hardware, enterprise consortiums pooling capacity for shared models), then the price comparison to Together.ai or DeepSeek becomes less relevant, because there is no centralized alternative to compare against.
The first path competes on economics. The second creates a market that does not exist yet. If access is the real differentiator, the question is whether that market is large enough to sustain these networks.
Does the Market Exist Yet?
CoreWeave generated $5.1 billion in revenue in 2025, with a $56 billion revenue backlog and 250,000+ GPUs across 32 data centers. The entire decentralized compute sector’s lifetime revenue does not approach a single CoreWeave quarter. Decentralized compute is not replacing centralized infrastructure, and framing it that way is a losing argument.
The more honest framing is that decentralized networks serve demand that centralized providers physically cannot reach or commercially choose not to serve. The fragmented enterprise capacity, the privacy-constrained workloads, the jurisdictions where no major cloud provider operates, and the cooperative training models described earlier all fall outside what centralized infrastructure is built to handle. Taken together, the addressable market starts to look less like a niche and more like a category. Whether it becomes one depends on how quickly distributed training scales beyond mid-tier models, and whether the enterprises best positioned to supply that compute can legally participate in token-incentivized networks at all.
Regulatory Clarity, Finally
One risk that has partially resolved itself: the regulatory overhang on token-based compute earnings. On March 17, 2026, the SEC and CFTC issued a joint interpretation establishing a five-category classification framework for crypto assets. Under this framework, protocol-level mining and staking activity generally falls outside securities treatment, with rewards viewed as compensation for services rather than investment returns. The safe harbor covers fully permissionless arrangements where rewards are determined by the protocol itself, which describes Bittensor’s model almost exactly. Six months ago, the question of whether TAO emissions constituted unregistered securities was a real risk to the entire participation model. That risk has not disappeared entirely, but the regulatory direction is now substantially clearer. There is also an interesting structural consequence: the GENIUS Act prohibits stablecoin issuers from paying interest to holders, but the SEC/CFTC framework treats compute rewards as compensation for services. If passive yield is restricted but active participation is not, that distinction could channel capital toward productive compute networks rather than passive holdings.
Where Is This Going?
If the economics do not work yet and the scale gap with centralized providers is enormous, why pay attention?
Because the gap is narrowing from both directions at the same time.
The Gap Narrows From Both Sides
From below, coordination breakthroughs are pushing decentralized networks upward. SparseLoCo’s 146x compression and DiLoCoX’s overlap techniques already proved that 70+ servers can coordinate over standard internet connections. On inference, Google Research just published TurboQuant at ICLR 2026, a drop-in compression algorithm that reduces model working memory by at least 6x and delivers up to 8x speedup with zero accuracy loss. In distributed setups where inference is split across multiple servers, 6x less data to transfer directly improves the feasibility of the whole architecture.
From above, frontier capability is compressing into smaller models. Qwen 3.5 7B dramatically outperforms Qwen 1.5 72B on most benchmarks despite being a tenth the size. DeepSeek-V3 matched GPT-4-class performance at a fraction of the training cost, then published how they did it.

That compression raises a fair question: if frontier labs keep releasing better open-source base models, why train new ones at all? Because the value of distributed training is not replicating what labs already publish. It is fine-tuning and specializing on data those labs do not have: proprietary enterprise data, pooled industry datasets, regulated information that cannot leave a jurisdiction. As base models improve, so does the starting point for that specialization, meaning the sector-specific or privacy-constrained models that decentralized networks can produce become more capable with each generation, without those networks needing to match frontier training scale themselves.
From Coordination to Revenue
As coordination overhead falls and model capability compresses, the stranded enterprise capacity and privacy-locked workloads described earlier become viable revenue sources rather than theoretical use cases. The path to profitability runs through expanding what the network can do, not just reducing what it costs.
Whether that expansion happens fast enough is genuinely uncertain. Centralized providers are all racing to add capacity, and if centralized supply catches up to demand before decentralized networks build a meaningful revenue base, the structural opening narrows, though all are subject to the economic reality. If coordination improvements plateau before reaching frontier-adjacent scale, the network remains limited to workloads where location, privacy, or censorship-resistance matter more than raw capability.
Where Value Accrues
In the current stack, value concentrates at chip design (Nvidia, 75%-plus gross margins) and cloud operation (AWS, over $100 billion in annual revenue at 33-40% operating margins). Even CoreWeave carries $14 billion in debt and posted a net loss of $1.17 billion on $5.13 billion in revenue in 2025 because GPU depreciation eats gross margins. If a disaggregated stack develops alongside this, where does value concentrate?
The Coordination Layer
The intuitive answer is the protocols that match GPU supply with compute demand. Coordination layers clearly can capture value: OpenRouter built a large developer base by routing API requests across centralized LLM providers, handling fallback, cost optimization, and a unified API. Developers stick with it despite being able to go direct to every provider it aggregates.
But OpenRouter coordinates a small number of known providers with stable APIs and contractual relationships. Decentralized compute coordination is a harder problem: anonymous operators, variable hardware, no contracts, permissionless onboarding, and the need for verification that work was performed correctly. The risk is that GPU operators multi-home across protocols, io.net aggregates from existing deployments including other decentralized networks, and tools for auto-switching to the most profitable protocol already exist. But the harder the coordination problem, the stickier the solution. Whoever solves reliability, routing, and trust across anonymous infrastructure may hold more defensibility than the commodity brokerage framing suggests.
Verification as the Defensibility Layer
The layer with stronger defensibility may be verification: proving that computation was performed correctly on untrusted hardware. Gensyn’s Verde system uses refereed delegation and a novel library called RepOps that enforces bitwise-reproducible results across diverse GPU hardware, solving the problem that the same matrix multiplication gives different results on different chips depending on operation ordering. This is technically difficult, genuinely novel, and a prerequisite for enterprise adoption, because without it, decentralized compute requires trusting anonymous operators. ZK-based verification costs orders of magnitude more than the computation itself; Verde achieves it at less than one order of magnitude overhead. If verification becomes the standard trust layer, whoever controls that infrastructure occupies a position similar to Chainlink in the oracle market, which became the default data feed layer that most of DeFi quietly depends on, by solving a problem that is easy to underestimate and hard to replicate.
The Rest of the Stack
Beyond protocols, three layers that do not yet exist in mature form:
Confidential compute (TEE orchestration, attestation): the privacy layer that makes regulated workloads possible on untrusted infrastructure. Intel and Nvidia are building the silicon; orchestration and compliance tooling is wide open.
Enterprise integration (onboarding, compliance, audit trails): companies will not plug GPU clusters into crypto networks without middleware for identity, regulatory reporting, and SLAs. Unsexy infrastructure with real switching costs.
Payment and settlement (x402, agentic wallets, stablecoin rails): necessary plumbing for machine-to-machine transactions, likely commoditized as providers converge on standard protocols.
What to Watch
Distributed training has gone from theoretical to functional in under a year, inference marketplaces will consolidate toward a small number of dominant protocols, and the SEC/CFTC framework has cleared a regulatory barrier that was blocking institutional participation. Those are developments already in motion. The open questions that determine whether this becomes a real market or remains a crypto subsidy experiment:
Does the subsidy ratio improve? If the 22-to-1 ratio stays flat or widens after the next halving, the model is not working.
Do enterprise operators join? If networks remain crypto-native operators only, the addressable supply stays small.
Does coordination scale to frontier-adjacent performance? A distributed model matching frontier benchmarks through better data or specialization would change the conversation entirely.
Do centralized providers close the supply gap first? If hyperscaler capacity catches up before decentralized networks build revenue, the structural opening narrows.
Does a verification standard emerge? If verification fragments or remains optional, enterprise workloads stay on centralized cloud.
The structural conditions that created this opportunity, physical supply constraints that cannot be solved by spending more money combined with frontier capability compressing into trainable model sizes, are not going away. Whether a second compute market emerges at meaningful scale depends on how these questions resolve over the next 12 to 18 months.