

The AGI Lab Dominating AI's Most Underestimated Metric

On Wednesday, Inclusion AI, the dedicated AGI lab of Ant Group (the global technology group behind Alipay), released Ling-2.6-flash: a 104-billion-parameter (7.4B active) open-source MoE model (256 expert modules, hybrid linear attention) that used up to 86% fewer tokens than comparable models to complete the same industry benchmark. It had already been running anonymously on OpenRouter as “Elephant Alpha”, where it topped the trending charts and hit 100 billion daily token calls.
Inclusion AI built a model for the agent economy, where thousands of tasks run in loops, every output token costs money, and the model that wastes the least wins. Very few labs optimize for intelligence per output token, despite it being one of the most important metrics in agentic AI. We ran tests against two comparable open-source models. Ling was the only one to complete all of them.
The Token Explosion
OpenRouter processed 20.6 trillion tokens just last week.
That’s roughly 2.4 million complete works of Shakespeare.
Per day.
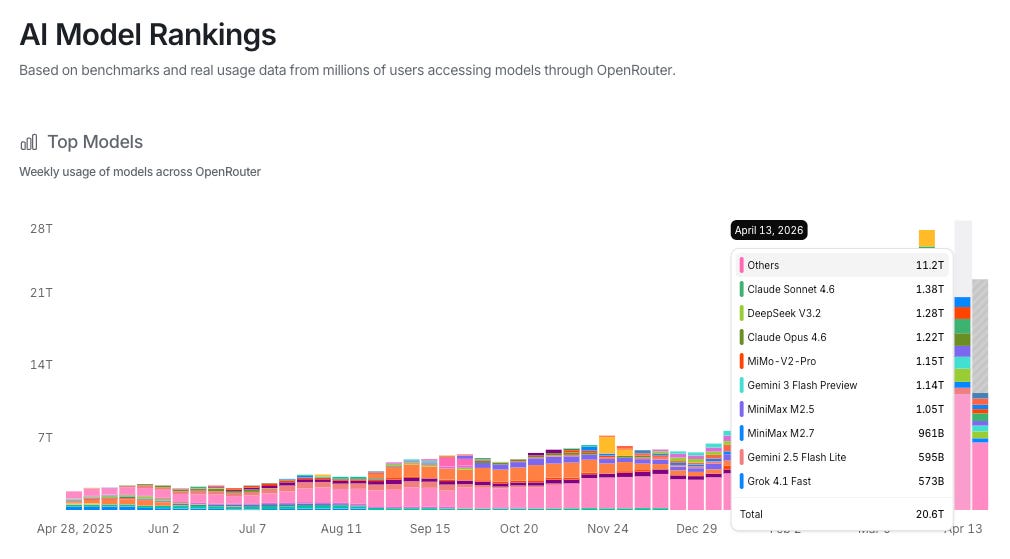
The driver isn’t chatbots. It’s agents. Anthropic’s own data: agents use roughly 4x more tokens than chat interactions. Multi-agent systems use 15x. Platforms like OpenClaw are running tasks around the clock. As Anand Iyer of Canonical VC put it: “The demand for AI inference right now is coming from agentic platforms, especially OpenClaw.”
At this volume, every wasted token is real money. Claude Sonnet 4.6 alone processed 1.38 trillion tokens last week on OpenRouter. The OpenRouter State of AI report puts average prompt tokens at 6,000 per request versus 400 for completions, a 15:1 input-to-output ratio. Applied to Sonnet’s traffic, that works out to roughly $5.2M at list price ($3/M input, $15/M output) across one platform in seven days.
The Overthinking Problem
The industry’s answer to “make it better” has been “make it bigger.” The result: top models now use tens of millions to hundreds of millions of output tokens to complete the same evaluation on the Artificial Analysis Intelligence Index. The arms race has been chasing intelligence scores while ignoring what it costs to get them.
Users have noticed. “Caveman prompting” strips grammar from inputs to force shorter outputs. The instruction prompt: “Speak primitive. Use nouns and verbs. No grammar filler. Save tokens.” A formalized Claude Code skill built around the technique has 14,000 GitHub stars. Its README written in the style it teaches: “Brain still big. Cost go down forever. One rock. That it.” Across real dev tasks, it cuts output tokens by 65%. It works for coding. It breaks on anything that requires sustained reasoning.
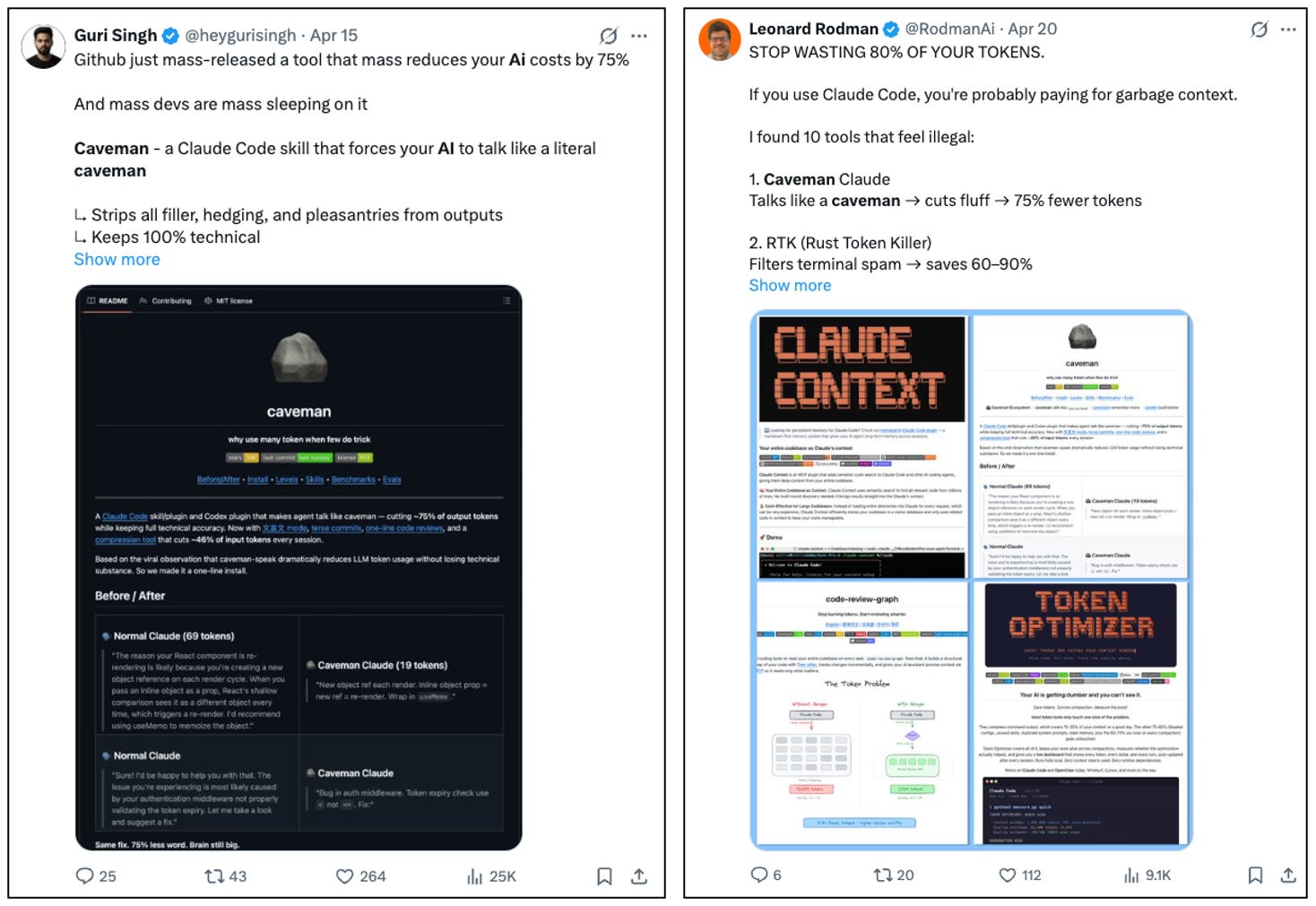
At the corporate level, the opposite problem: tokenmaxxing. Companies began tracking employee token consumption as a productivity metric. Workers compete on internal leaderboards ranked by tokens burned, with the highest individual user averaging 281 billion tokens. Volume confused for value.
The instinct isn’t limited to prompt engineering. Marc Andreessen recently called a YouTuber with “a hundred videos on retardmaxxing” his “new life coach.” The philosophy: go to work, do a good job, come home. Don’t overthink it. Chamath Palihapitiya said the same on All-In: “Enjoy your life, work hard, and don’t overthink it.”
Caveman prompting is the demand-side version of this: users forcing models to stop overproducing. But the hack reduces cost without reducing waste. A model that produces fewer tokens because it reasons more efficiently is a different proposition from one that’s been told to shut up. What if a model just didn’t overproduce by design?
The Intelligence Yield Thesis
“Bigger is better” has peaked. The new competition is fewer active parameters, faster inference, lower cost per completed task.
Mixture-of-Experts architectures route each token to a small subset of the total parameters. What matters is how many fire per token, not how many exist. Linear attention scales computation linearly instead of quadratically, an advantage that compounds as outputs get longer.
The focus should be on outcome per token.
Ant Group and Ling-2.6-flash
Ant Group’s dedicated AGI lab was launched in February 2025, inspired by DeepSeek’s research model. Their stated vision: “AGI as humanity’s shared milestone, not a privileged asset.”
Ant Group’s DNA is financial inclusion: 140 million healthcare users on AQ, 60% from cities where specialist care barely exists; 1.69 million farmers with satellite-assessed, collateral-free loans processed in minutes. Chairman Eric Jing calls it “inclusive AI.”
Ling-2.6-flash is in our opinion one of the models on the Pareto frontier of the Intelligence Yield Thesis. (We’re also big fans of Minimax M2.7, which leads in a different quadrant).
The architecture: 104 billion total parameters, 7.4 billion active per token. MoE with 256 expert modules. Hybrid Linear Attention + Multi-head Latent Attention with linear time complexity, where the advantage grows at longer outputs. Multi-Token Prediction for parallel inference.
The efficiency: 15 million output tokens to complete the full Artificial Analysis eval. The comparison models used 5-7x more.
Before anyone knew who made it, Ling launched on OpenRouter as “Elephant Alpha.” Topped the trending charts. Hit 100 billion daily token calls. Top 8 by total calls on the platform. Without brand or marketing, the model proved itself.
First, some context on benchmark results before we dive into the tests (images from artificialanalysis.ai).
The Benchmarks
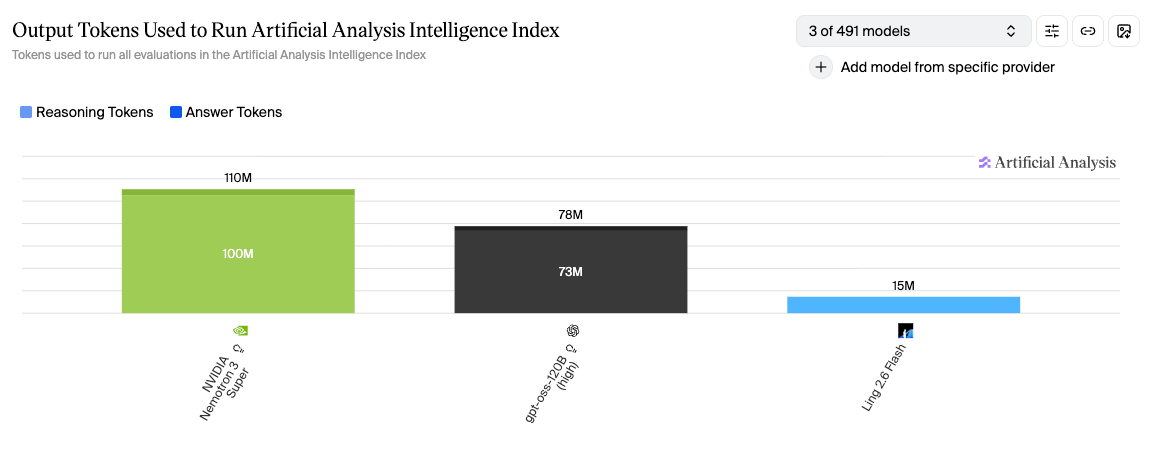
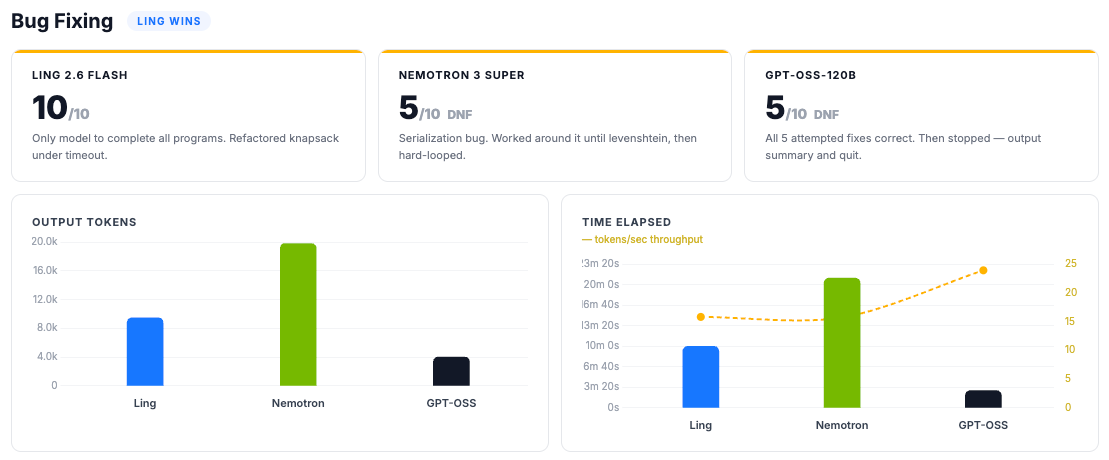
Token use
Nemotron used 110 million output tokens to complete the standardized AA Intelligence Index. GPT-OSS used 78 million. Ling used 15 million. That’s 86% fewer tokens than Nemotron and 81% fewer than GPT-OSS.
Cost
Multiply by price per token. Ling: $23. GPT-OSS: $67. Nemotron: $145.
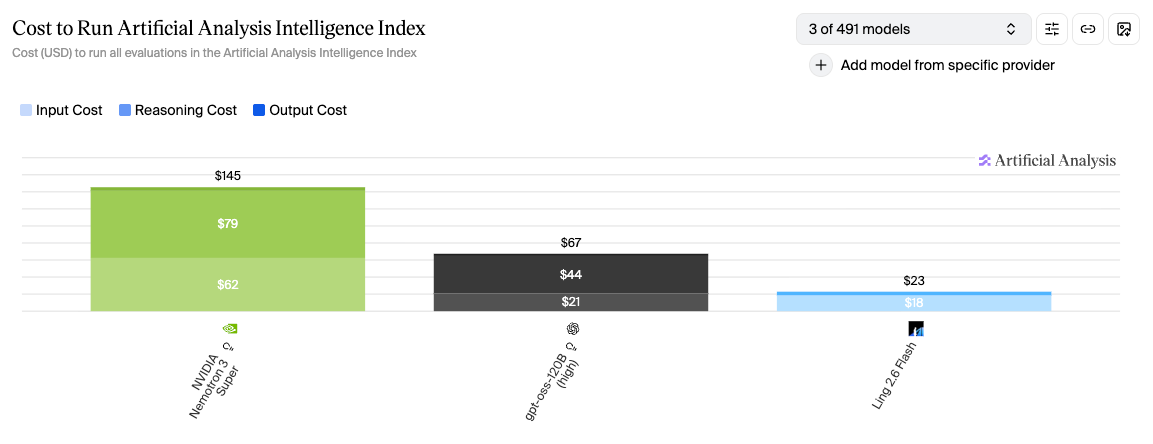
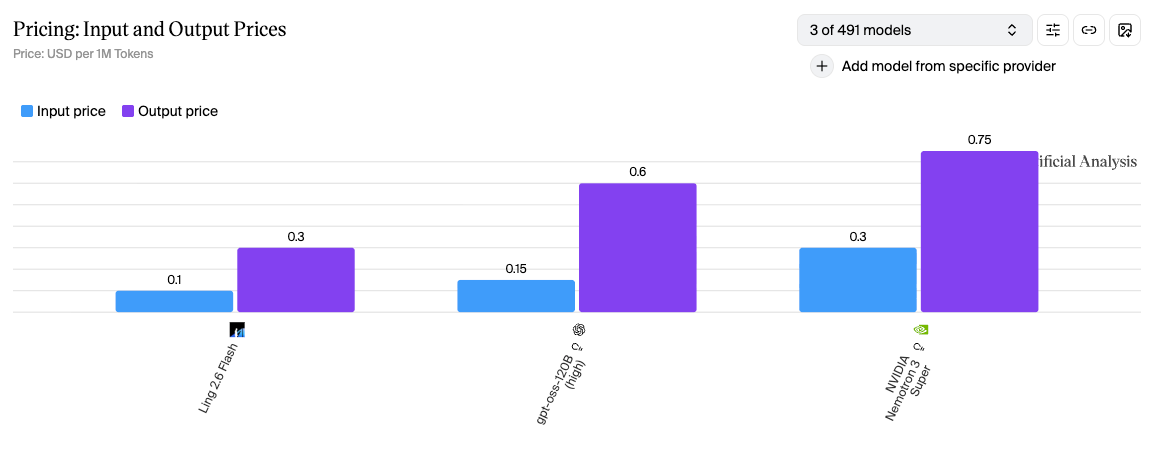
Model Pricing
Cheap per-token pricing doesn’t guarantee cheaper outcomes. GPT-OSS charges 2x more per output token than Ling ($0.60 vs $0.30) and uses 5x more output tokens. Factor in input costs and the total comes to $67 vs $23 for the same evaluation.
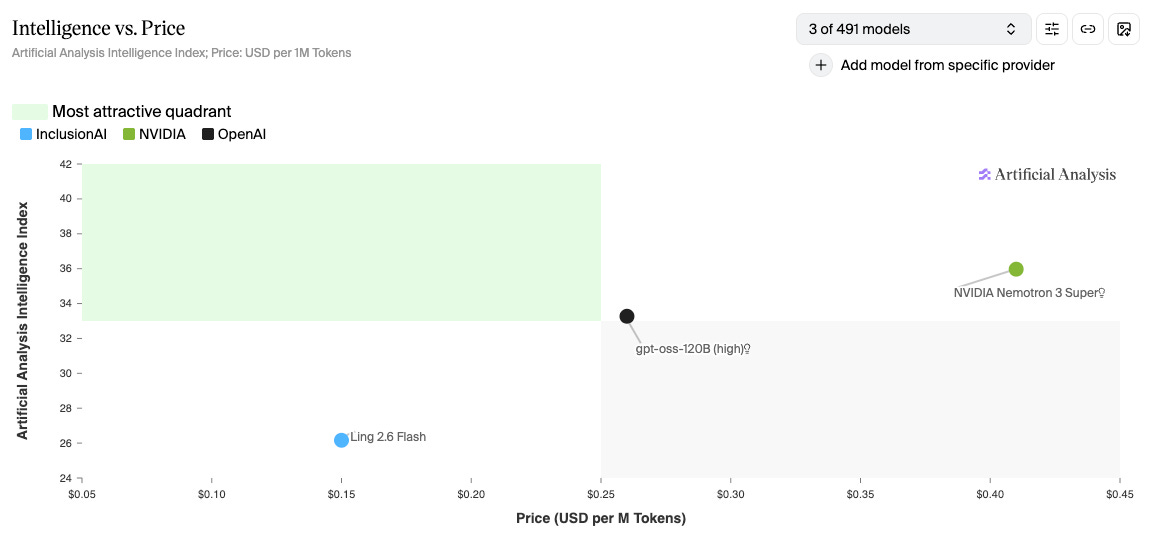
Intelligence
This is the chart where Ling looks weakest. Intelligence score: 26, against GPT-OSS’s 33 and Nemotron’s 36.
The benchmark results call to mind a quote by someone who knew a thing or two about intelligence.

The AA Intelligence Index measures general reasoning, knowledge, and math. It does not measure sustained execution in loops, tool use across hundreds of steps, or the ability to finish what it starts. In testing, Ling was the only model that did.
Let the Tokens Do the Talking
Three tests, run through Claude Code: qualitative analysis, bug fixing, and visual code generation. Ling against two open-source models in the same weight class: Nemotron-3-Super-120B (12B active), Inclusion AI’s own published benchmark rival, and GPT-OSS-120B, OpenAI’s open-source entry. Same prompts, same tools, same environment. Every token tracked.
Qualitative Analysis
For this test we wanted to check qualitative verbal reasoning in addition to simple tool calling. Each model was given a one-paragraph brief and asked to grab the latest news and produce a vibe check on today’s tech: sources, an overall vibe read, companies vibing and not vibing, and a one-paragraph synthesis. Take a position, back it with reasoning, and convey it in an output file, blind-scored by Gemini 3.1 Pro on voice, judgment, and second-order thinking.
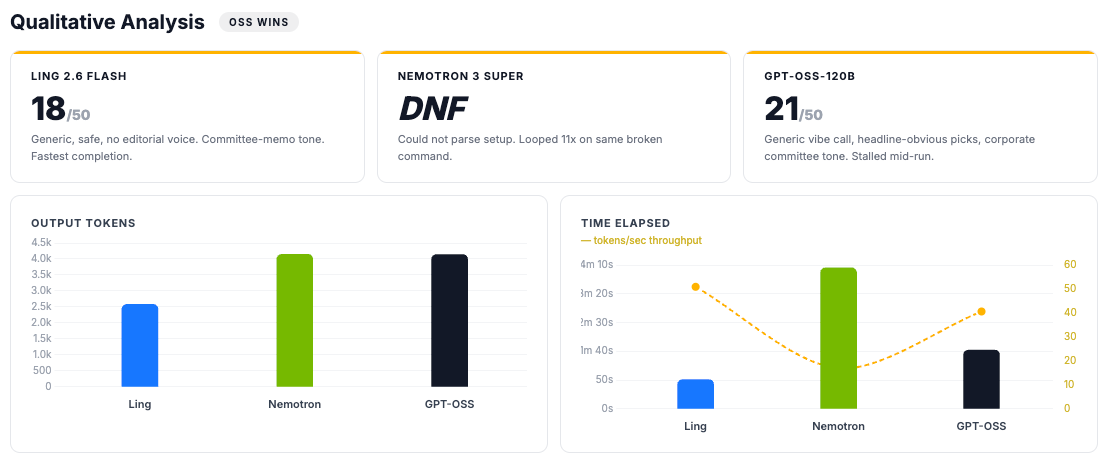
Ling 2.6 Flash: 18/50: Finished in 2,579 tokens, 50.7 seconds. Hedged every observation, described the surface without reading beneath it.
GPT-OSS-120B: 21/50: Similar tone. Generic vibe call, headline-obvious picks. Gemini flagged both for consultant-speak. Better discipline score kept it three points ahead.
Nemotron 3 Super: Did Not Finish (DNF): Never started. Couldn’t parse the setup step and emitted garbled Python-serialized output instead of clean bash. Repeated the same broken command 11 times, mid-loop it ran
echoandpwdsuccessfully, proving basic bash execution was fine, then immediately returned to the broken pattern. Same serialization bug that surfaced in all three tests. 4,145 tokens spent, nothing produced.
Bug Fixing
Ten programs from QuixBugs: classic algorithm implementations, each with exactly one introduced bug. The task: find the bug, fix it, pass the tests.
Ling 2.6 Flash: 10/10: Fixed all ten. On knapsack, a large input triggered a test harness timeout. Ling identified the performance constraint and refactored iterative DP to recursive with
@lru_cache, going beyond the one-line fix to make the algorithm pass within the test harness timeout.Nemotron 3 Super: 5/10, DNF: A serialization bug appeared across all three tests: instead of clean code output, the model produced Python-serialized data structures. It worked around this for the first five programs. On Levenshtein distance, the bug triggered an infinite loop it never escaped.
GPT-OSS-120B: 5/10, DNF: Fixed every program it attempted (gcd, flatten, mergesort, quicksort, find_in_sorted), all correct on first try. Then stopped. After program five, it output a summary of remaining tasks and quit. We relaunched it to confirm: same result. No error, loop, or technical failure, it simply didn’t sustain the task.
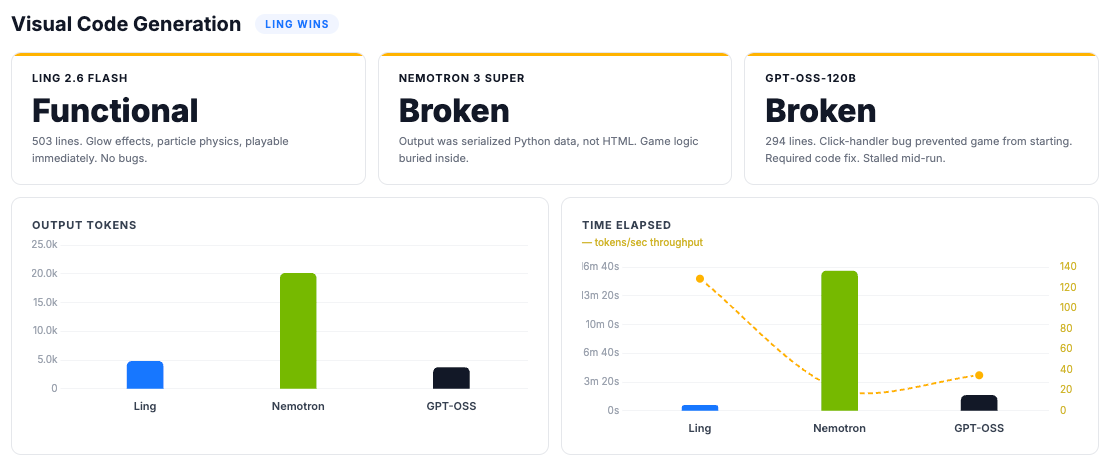
Visual Code Generation
Breakout game, single-file HTML. One prompt, no follow-ups.
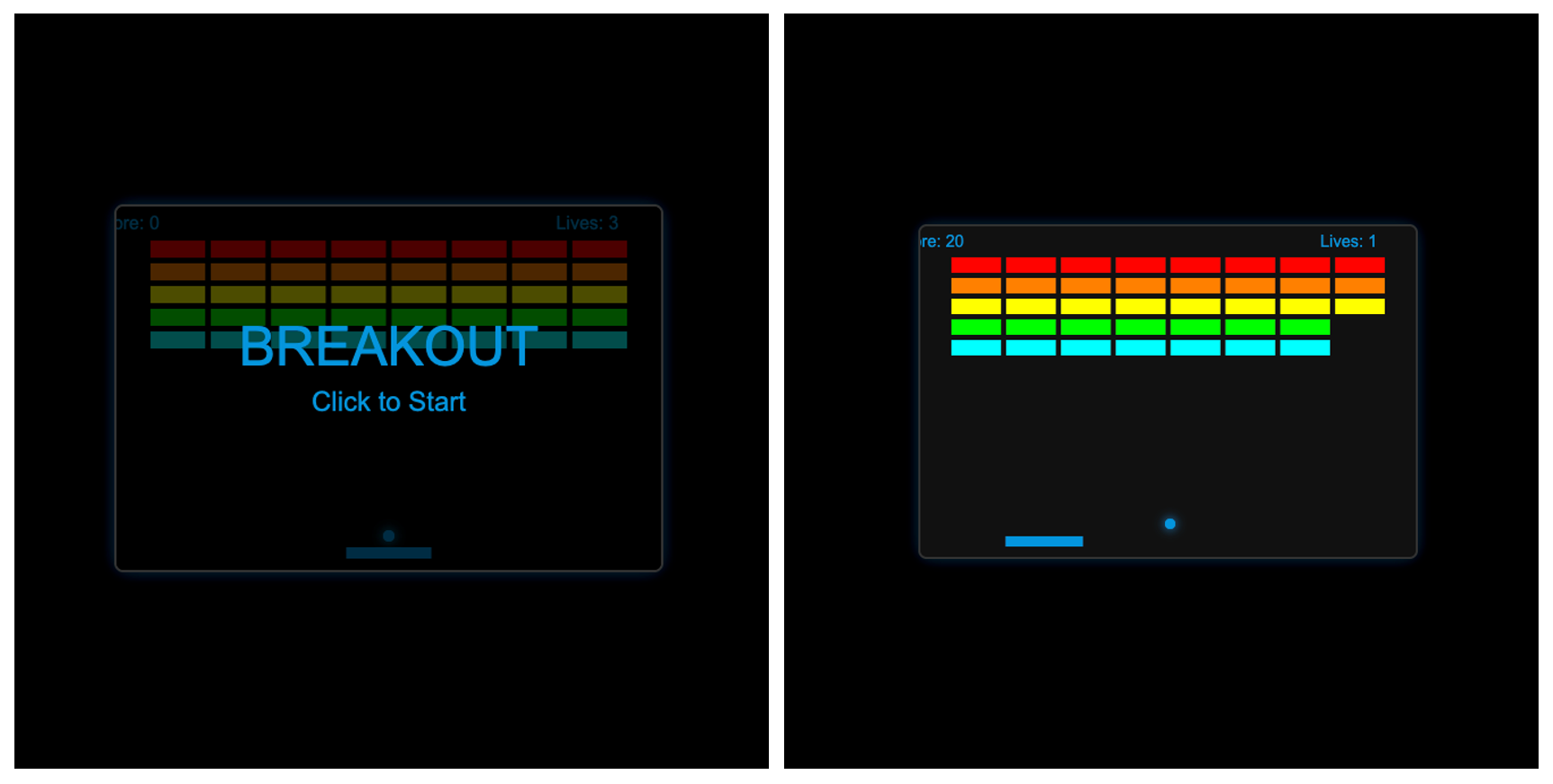
Ling 2.6 Flash: Functional: 503 lines. Glow effects, particle physics, working game mechanics. No debugging, no reconstruction, no workarounds. Played immediately.
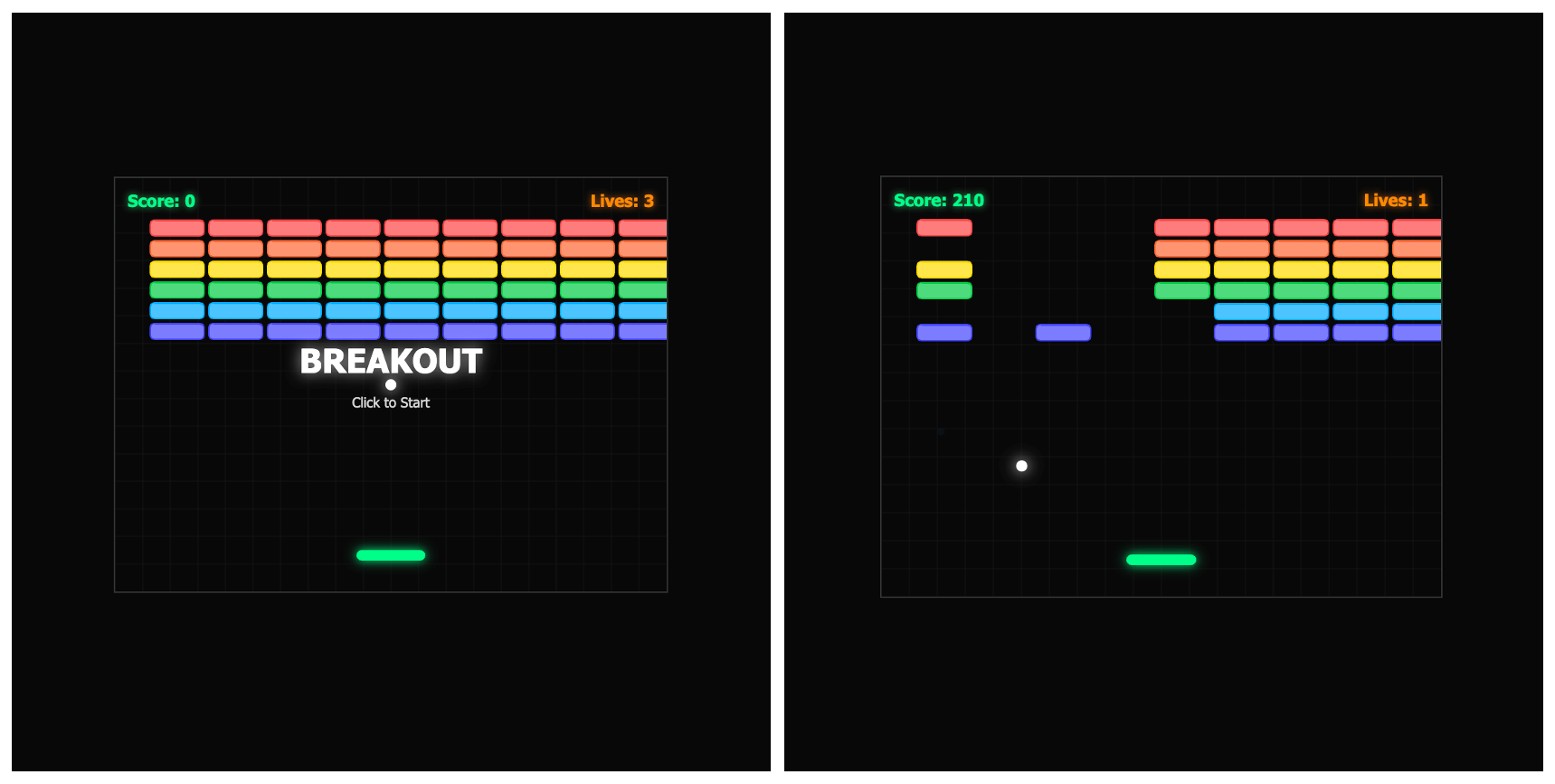
GPT-OSS-120B: Broken on delivery: 294 lines. The game logic was there (paddle, ball, bricks, collision, particles) but it didn’t work out of the box: the start screen overlay blocked click events from reaching the canvas, so the game couldn’t actually be started without a code fix. Simpler than Ling’s output: flat-colored bricks, minimal effects, smaller canvas. Same mid-task stall as the other two tests: froze mid-generation, required prompting to continue.

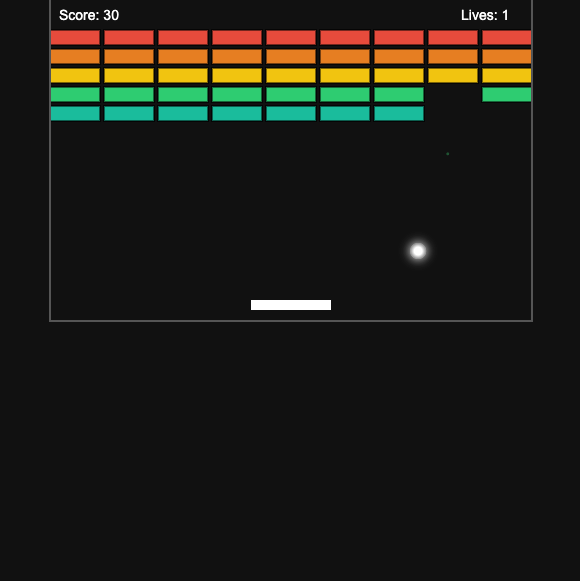
Nemotron 3 Super: Broken: Same serialization bug as in the bug-fixing test. Produced Python-serialized data instead of HTML. The game logic was there but was buried inside a model-level format failure that affected all three tests. We reconstructed it from the raw output; the logic held up pretty well once extracted. Though there were layout bugs.

The Results
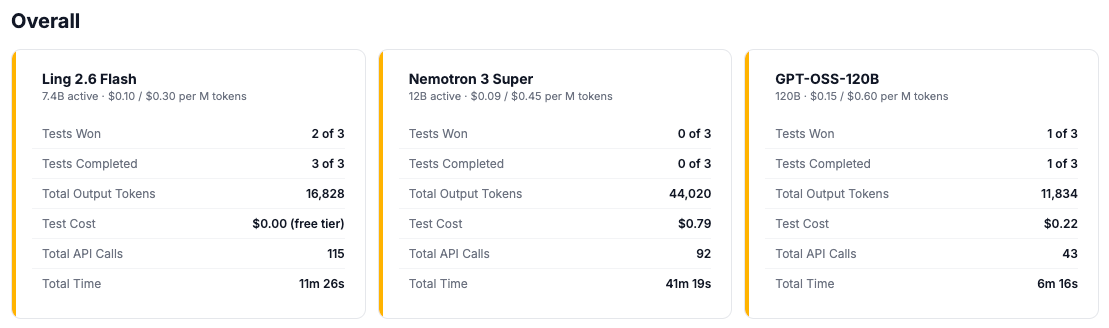
Across all three tests, Ling was the only model to complete every task without intervention. The competition failed in different ways: Nemotron’s serialization bug blocked it in every test. OSS was competent when working (every bug fix correct) but stalled mid-run across all three tests, each time requiring a prompt to continue, and its visual output didn’t work without a code fix. Completion and token efficiency moved together.
A model that uses fewer tokens per step can sustain more steps before losing coherence. The same design discipline that cuts token waste also cuts task abandonment. The tradeoff showed in qualitative analysis, where Ling scored lowest: a model trained to minimize output tokens will hedge rather than elaborate, summarize rather than argue. The same discipline that makes it fast at execution makes it flat on opinion.
The AA Intelligence Index doesn’t test what agents actually do. The benchmarks that do tell a different story. BFCL-V4 measures function calling accuracy: Ling 67.04, GPT-OSS 43.3, Nemotron 35.12. TAU2-Telecom measures multi-step task completion: Ling 93.86, Nemotron 62.94, GPT-OSS 41.45. SWE-bench Verified: Ling 62.00, Nemotron 61.00, GPT-OSS 43.80. MRCR long-context: Ling 54.01, Nemotron 39.04. Ling leads on agentic benchmarks across the board. It trails Nemotron on hard math (AIME 73.80 vs 88.59).



Different tool for a different job.
Why This Is Important
Andrej Karpathy’s autoresearch makes this concrete. A coding agent autonomously improves a training script in a loop: read, hypothesize, edit, run, evaluate, repeat. Unattended. Karpathy ran it for two days: 700 experiments, 20 discovered optimizations, 11% training speedup. Shopify CEO Tobi Lütke tried it overnight: 37 experiments, +19%.
Each cycle: roughly 18,000 tokens at about $0.10. At 700 cycles, the gap between an efficient model and a verbose one is the gap between a $70 run and a $700 run.
The same pattern applies everywhere agents run in loops: CI pipelines, code review, data monitoring, agent swarms. The emerging architectures don’t use one model for everything. Frontier models like Kimi K2.6 and Claude Sonnet are strong at complex reasoning and high-stakes decisions. But running them on every sub-task in a multi-agent pipeline is expensive by design. Kimi K2.6 at $0.75/$3.50 per million tokens, Claude Sonnet at $3/$15. Efficient models handle execution-layer throughput at a fraction of the cost.
A swarm running hundreds of sub-tasks needs each sub-agent to be reliable, cheap, and disciplined, not the smartest model available. At $0.10/$0.30 versus $3/$15, that choice determines whether a pipeline is economically viable at scale.
The cost floor dropping changes what’s possible. Always-on agents that monitor, iterate, and improve without human intervention. A researcher annotating genomic data in a continuous loop. A solo developer running hundreds of test variations overnight. A clinic in a mid-tier city running diagnostic pipelines on a budget that would not have supported it a year ago. The compute and models exist. The constraint has been a reliable model with good cost per token at volume.
Ling at $0.10/$0.30, open-source, designed to minimize waste. That’s the financial inclusion bet applied to intelligence itself.
20.6 trillion tokens last week. The agent economy is here. Efficiency is the core driver. Inclusion AI is building for it.